Redis基础
Redis基础
简介
Redis是一个开源( BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件MQ。它支持多种类型的数据结构,如字符串( strings),散列( hashes) ,列表(lists),集合(sets),有序集合( sorted sets)与范围查询,bitmaps,hyperloglogs和地理空间( geospatial )索引半径查询。Redis 内置了复制(replication) , LUA脚本( Luascripting),LRU驱动事件( LRU eviction) , 事务( transactions )和不同级别的磁盘持久化( persistence ), 并通过Redis哨兵( Sentinel )和自动分区( Cluster )提供高可用性( high availability)。
基础命令的使用
127.0.0.1:6379> keys *
1) "a6d67fc760183455c4873edbe90feccd"
2) "54387c3e9203809d6bb0288274769c43"
3) "oauth:client:details::web"
4) "5db802e935ab9bb62593d914b8bc1e26"
127.0.0.1:6379> flushdb # 清除db内的所有数据
OK
127.0.0.1:6379> set name pzy # 设置一个值
OK
127.0.0.1:6379> keys * # 查看所有的key
1) "name"
127.0.0.1:6379> get name # 获取key所对应的值
"pzy"
127.0.0.1:6379> EXISTS name # 查看是否存在此key
(integer) 1
127.0.0.1:6379> MOVE name 1 # 移除key
(integer) 1
127.0.0.1:6379> EXPIRE name 10 # 设置key的过期时间
(integer) 1
127.0.0.1:6379> ttl name # 查询key还有多长时间过期
(integer) 4
127.0.0.1:6379> ttl name # 值为-2时说明key已经过期
(integer) -2
127.0.0.1:6379> get name # 过期后key的值为nil
(nil)
127.0.0.1:6379> type name # 获取key的类型
string
String(字符串)
127.0.0.1:6379> append name 123 # 在值的后面追加字符串,如果当前key不存在就相当于setkey
(integer) 6
127.0.0.1:6379> get name
"pzy123"
127.0.0.1:6379> strlen name # 获取字符串的长度
(integer) 6
127.0.0.1:6379> set view 0
OK
127.0.0.1:6379> get view
"0"
127.0.0.1:6379> incr view # 自增1
(integer) 1
127.0.0.1:6379> incr view
(integer) 2
127.0.0.1:6379> get view
"2"
127.0.0.1:6379> decr view # 自减1
(integer) 1
127.0.0.1:6379> decr view
(integer) 0
127.0.0.1:6379> get view
"0"
127.0.0.1:6379> INCRBY view 10 # 可以设置步长设置增量
(integer) 10
127.0.0.1:6379> INCRBY view 10
(integer) 20
127.0.0.1:6379> DECRBY view 10 # 可以设置步长设置减量
(integer) 10
127.0.0.1:6379> GETRANGE name 0 3 # 截取字符串的长度,下标从0开始
"pzy1"
127.0.0.1:6379> SETRANGE name 3 666 # 替换指定位置开始的值
(integer) 6
127.0.0.1:6379> get name
"pzy666"
127.0.0.1:6379> setex age 30 "100" # 设置一个值并且设置过期时间(set with expire)
OK
127.0.0.1:6379> get age
"100"
127.0.0.1:6379> ttl age
(integer) 16
127.0.0.1:6379> setnx age 1000 # 不存在这个key才会去设置值(set if not exist),分布式锁中会常常使用
(integer) 0
127.0.0.1:6379> get age
"100"
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # 量设置值
OK
127.0.0.1:6379> keys *
1) "k2"
2) "k1"
3) "k3"
127.0.0.1:6379> mget k1 k2 k3 #批量获取值
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k5 v5 # 是一个原子性操作,要么一起成功,要么一起失败
(integer) 0
127.0.0.1:6379> keys *
1) "k2"
2) "k1"
3) "k3"
127.0.0.1:6379> mset user:1:name pzy user:1:age 20 # 设置一个key,中间冒号隔开,在项目中可以分组区分是哪个模块下的缓存
OK
127.0.0.1:6379> mget user:1:name user:1:age # 获取也可以使用这种key的方式获取值
1) "pzy"
2) "20"
127.0.0.1:6379> getset db redis # 先get旧值再set新值,如果不存在值为nil
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongdb
"redis"
List(列表)
在redis里面,可以把list玩成栈、队列、阻塞队列
所有list命令都是用L开头的
127.0.0.1:6379> LPUSH list one two three # 往list中插入值,插入到列表头部
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1 # 获取list中的全部值
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> LRANGE list 0 1 # 获取下标[0,1]的值
1) "three"
2) "two"
127.0.0.1:6379> RPUSH list zero # 往list中插入值,插入到列表尾部
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "one"
4) "zero"
127.0.0.1:6379> LPOP list # 移除头部一个值(第一个值)
"three"
127.0.0.1:6379> RPOP list # 移除尾部一个值(最后一个值)
"zero"
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "one"
127.0.0.1:6379> LINDEX list 1 # 通过下标获取list中的某一个值
"one"
127.0.0.1:6379> LINDEX list 0
"two"
127.0.0.1:6379> LLEN list # 获取list长度
(integer) 2
127.0.0.1:6379> LPUSH list zero three three
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "three"
3) "zero"
4) "two"
5) "one"
127.0.0.1:6379> LREM list 1 one # 移除一个值为one的元素
(integer) 1
127.0.0.1:6379> LREM list 1 three # 移除一个值为three的元素(参数3为移除个数)
(integer) 1
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "zero"
3) "two"
127.0.0.1:6379> LTRIM list 1 2 # 通过下标截取指定长度,并重新赋值到list中
OK
127.0.0.1:6379> LRANGE list 0 -1
1) "zero"
2) "two"
127.0.0.1:6379> RPOPLPUSH list mylist # 将list中的最后一个元素移除,并添加到新的集合中
"two"
127.0.0.1:6379> LRANGE list 0 -1
1) "zero"
127.0.0.1:6379> LRANGE mylist 0 -1
1) "two"
127.0.0.1:6379> LSET list 0 item # 将指定下标的元素替换,下标不存在报错
OK
127.0.0.1:6379> LRANGE list 0 -1
1) "item"
127.0.0.1:6379> LINSERT list before item hello # 将某个值插入到集合某元素前面
(integer) 2
127.0.0.1:6379> LINSERT list after item world # 将某个值插入到集合某元素后面
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1
1) "hello"
2) "item"
3) "world"
Set(集合)
127.0.0.1:6379> SADD set hello zhangsan lisi wangwu # 往set集合中添加元素
(integer) 4
127.0.0.1:6379> SMEMBERS set # 查看set中的所有值
1) "wangwu"
2) "hello"
3) "zhangsan"
4) "lisi"
127.0.0.1:6379> SISMEMBER set hello # 判断某一个值存不存在,存在返回1,不存在返回0
(integer) 1
127.0.0.1:6379> SISMEMBER set world
(integer) 0
127.0.0.1:6379> SCARD set # 获取set的长度
(integer) 4
127.0.0.1:6379> SREM set hello # 移除set中的指定元素
(integer) 1
127.0.0.1:6379> SMEMBERS set
1) "wangwu"
2) "zhangsan"
3) "lisi"
127.0.0.1:6379> SRANDMEMBER set # 随机获取指定个数个值,默认取一个
"lisi"
127.0.0.1:6379> SRANDMEMBER set
"lisi"
127.0.0.1:6379> SRANDMEMBER set
"zhangsan"
127.0.0.1:6379> SRANDMEMBER set 2
1) "wangwu"
2) "lisi"
127.0.0.1:6379> SPOP set # 随机删除指定个数个值,默认取一个
"lisi"
127.0.0.1:6379> SMEMBERS set
1) "wangwu"
2) "zhangsan"
127.0.0.1:6379> SMOVE set myset wangwu # 将指定元素从一个集合移动到另外一个集合
(integer) 1
127.0.0.1:6379> SMEMBERS set
1) "zhangsan"
127.0.0.1:6379> SMEMBERS myset
1) "wangwu"
127.0.0.1:6379> SADD set wangwu
(integer) 1
127.0.0.1:6379> SDIFF set myset # 差集
1) "zhangsan"
127.0.0.1:6379> SINTER set myset # 交集
1) "wangwu"
127.0.0.1:6379> SUNION set myset # 并集
1) "wangwu"
2) "zhangsan"
Hash(哈希)
相当于Map
127.0.0.1:6379> HSET myhash key1 val1 # 设置hash值
(integer) 1
127.0.0.1:6379> hget myhash key1 # 获取一个hash值
"val1"
127.0.0.1:6379> HMSET myhash key1 hello key2 world # 批量设置hash值
OK
127.0.0.1:6379> HMGET myhash key1 key2 # 批量获取hash值
1) "hello"
2) "world"
127.0.0.1:6379> HGETALL myhash # 获取全部的hash值
1) "key1"
2) "hello"
3) "key2"
4) "world"
127.0.0.1:6379> HDEL myhash key2 # 删除指定的hash值
(integer) 1
127.0.0.1:6379> HGETALL myhash
1) "key1"
2) "hello"
127.0.0.1:6379> HLEN myhash # 获取hash的长度
(integer) 1
127.0.0.1:6379> HEXISTS myhash key1 # 判断某一个值存不存在,存在返回1,不存在返回0
(integer) 1
127.0.0.1:6379> HEXISTS myhash key2
(integer) 0
127.0.0.1:6379> HKEYS myhash # 获取hash中的所以key
1) "key1"
127.0.0.1:6379> HVALS myhash # 获取hash中的所以value
1) "hello"
127.0.0.1:6379> HSET myhash key2 5 # 设置一个数值类型的hash
(integer) 1
127.0.0.1:6379> HINCRBY myhash key2 1 # value加一
(integer) 6
127.0.0.1:6379> HINCRBY myhash key2 -1 # value减一
(integer) 5
127.0.0.1:6379> HSETNX myhash key3 hello # 设置一个hash值,如果不存在则添加,如果存在则不改变值
(integer) 1
127.0.0.1:6379> HSETNX myhash key3 world
(integer) 0
127.0.0.1:6379> HGET key3
(error) ERR wrong number of arguments for 'hget' command
127.0.0.1:6379> HGET myhash key3
"hello"
Zset(有序集合)
127.0.0.1:6379> ZADD zset 1 val1 2 val2 3 val3 # 设置zset值
(integer) 3
127.0.0.1:6379> ZRANGE zset 0 -1 # 获取所有的zset值
1) "val1"
2) "val2"
3) "val3"
127.0.0.1:6379> zadd salary 5000 zhangsan 8000 liai 4000 wangwu
(integer) 3
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf # 排序从负无穷到正无穷(也就是从小到大排序)
1) "wangwu"
2) "zhangsan"
3) "liai"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores # 显示用户全部信息,从小到大
1) "wangwu"
2) "4000"
3) "zhangsan"
4) "5000"
5) "liai"
6) "8000"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf 5000 withscores
1) "wangwu"
2) "4000"
3) "zhangsan"
4) "5000"
127.0.0.1:6379> ZREVRANGE salary 0 -1 # 从大到小排序
1) "liai"
2) "zhangsan"
3) "wangwu"
127.0.0.1:6379> ZRANGE zset 0 -1
1) "val1"
2) "val2"
3) "val3"
127.0.0.1:6379> ZREM zset val3 # 移除某一元素
(integer) 1
127.0.0.1:6379> ZRANGE zset 0 -1
1) "val1"
2) "val2"
127.0.0.1:6379> ZCARD zset # 获取zset的长度
(integer) 2
127.0.0.1:6379> ZCOUNT zset -inf +inf # 获取指定区间的数量
(integer) 2
三种特殊类型
地理空间( geospatial )
底层基于zset,所以可以使用zset的命令移除
127.0.0.1:6379> GEOADD china:city 116.397128 39.916527 beijing # 添加地理位置(经度 纬度 名称)
(integer) 1
127.0.0.1:6379> GEOADD china:city 121.48941 31.40527 shanghai
(integer) 1
127.0.0.1:6379> GEOADD china:city 106.54041 29.40268 chongqing
(integer) 1
127.0.0.1:6379> GEOADD china:city 113.88308 22.55329 shenzhen
(integer) 1
127.0.0.1:6379> GEOADD china:city 87.615653 43.831501 xinjiang
(integer) 1
127.0.0.1:6379> GEOPOS china:city shanghai # 获取某个值,可以获取多个值
1) 1) "121.4894101023674"
2) "31.405269938483805"
127.0.0.1:6379> GEODIST china:city chongqing xinjiang km # 获取两个经纬度之间的距离,单位为km,默认是m,(还可以使用mi英里ft英尺)
"2319.5814"
127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km # 获取以100,30这个经纬度为中心,1000km内的城市
1) "chongqing"
2) "shenzhen"
127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km withcoord withdist count 1 # 获取以100,30这个经纬度为中心,1000km内的城市具体经纬度,限制显示的个数
1) 1) "chongqing"
2) "340.7667"
3) 1) "106.54040783643723"
2) "29.402680535172998"
127.0.0.1:6379> GEORADIUSBYMEMBER china:city shanghai 2000 km # 找出位于指定元素周围的其他元素
1) "chongqing"
2) "shenzhen"
3) "shanghai"
127.0.0.1:6379> GEOHASH china:city shanghai chongqing # 返回一个或多个位置元素的hash值,11位的hash
1) "wtw6st1uuq0"
2) "wm5z22s7520"
127.0.0.1:6379> ZRANGE china:city 0 -1 # 查询当前所以位置
1) "xinjiang"
2) "chongqing"
3) "shenzhen"
4) "shanghai"
127.0.0.1:6379> ZREM china:city shanghai # 移除某个位置
(integer) 1
127.0.0.1:6379> ZRANGE china:city 0 -1
1) "xinjiang"
2) "chongqing"
3) "shenzhen"
HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
127.0.0.1:6379> PFADD mykey a b c d e f g # 设置HyperLogLog值
(integer) 1
127.0.0.1:6379> PFCOUNT mykey # 查询HyperLogLog的基数
(integer) 7
127.0.0.1:6379> PFADD mykey2 a b c d
(integer) 1
127.0.0.1:6379> PFCOUNT mykey2
(integer) 4
127.0.0.1:6379> PFMERGE mykey3 mykey mykey2 # 合并mykey、mykey2到mykey3中
OK
127.0.0.1:6379> PFCOUNT mykey3
(integer) 7
127.0.0.1:6379>
bitmap
127.0.0.1:6379> SETBIT sign 0 1 # 设置bitmap值
(integer) 0
127.0.0.1:6379> SETBIT sign 1 0
(integer) 0
127.0.0.1:6379> SETBIT sign 2 1
(integer) 0
127.0.0.1:6379> SETBIT sign 3 1
(integer) 0
127.0.0.1:6379> GETBIT sign 3 # 获取bitmap值
(integer) 1
127.0.0.1:6379> GETBIT sign 0
(integer) 1
127.0.0.1:6379> BITCOUNT sign # 统计值为1的数量
(integer) 3
Redis持久化
redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失。幸好Redis还为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Append Only File)。
在这里假设你已经了解了redis的基础语法,某字母网站都有很好的教程,可以去看。基本使用的文章就不写了,都是一些常用的命令。
下面针对这两种方式来介绍一下。由浅入深。
一、持久化流程
既然redis的数据可以保存在磁盘上,那么这个流程是什么样的呢?
要有下面五个过程:
(1)客户端向服务端发送写操作(数据在客户端的内存中)。
(2)数据库服务端接收到写请求的数据(数据在服务端的内存中)。
(3)服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
(4)操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
(5)磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
这5个过程是在理想条件下一个正常的保存流程,但是在大多数情况下,我们的机器等等都会有各种各样的故障,这里划分了两种情况:
(1)Redis数据库发生故障,只要在上面的第三步执行完毕,那么就可以持久化保存,剩下的两步由操作系统替我们完成。
(2)操作系统发生故障,必须上面5步都完成才可以。
在这里只考虑了保存的过程可能发生的故障,其实保存的数据也有可能发生损坏,需要一定的恢复机制,不过在这里就不再延伸了。现在主要考虑的是redis如何来实现上面5个保存磁盘的步骤。它提供了两种策略机制,也就是RDB和AOF。
二、RDB机制
RDB其实就是把数据以快照的形式保存在磁盘上。什么是快照呢,你可以理解成把当前时刻的数据拍成一张照片保存下来。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
在我们安装了redis之后,所有的配置都是在redis.conf文件中,里面保存了RDB和AOF两种持久化机制的各种配置。
既然RDB机制是通过把某个时刻的所有数据生成一个快照来保存,那么就应该有一种触发机制,是实现这个过程。对于RDB来说,提供了三种机制:save、bgsave、自动化。我们分别来看一下
1、save触发方式
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下:
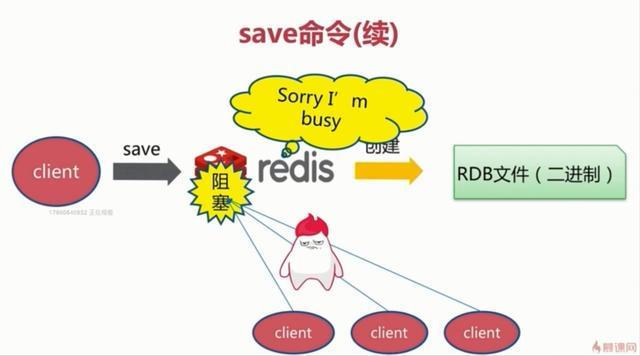
执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
2、bgsave触发方式
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
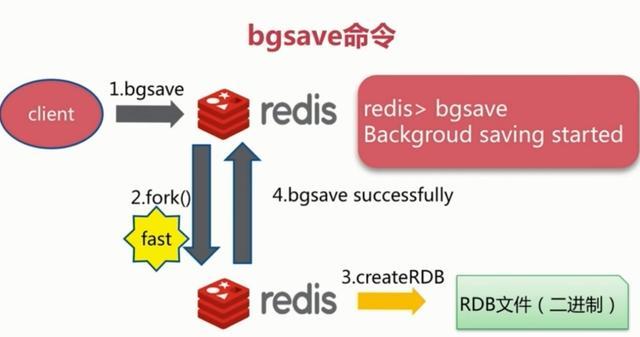
具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
3、自动触发
127.0.0.1:6379> FLUSHALL # 清除库中数据,也会生成一个dump.rdb文件
OK
自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
**①save:**这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
默认如下配置:
#表示900 秒内如果至少有 1 个 key 的值变化,则保存save 900 1#表示300 秒内如果至少有 10 个 key 的值变化,则保存save 300 10#表示60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000
不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。
**②stop-writes-on-bgsave-error :**默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
**③rdbcompression ;**默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
**④rdbchecksum :**默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
**⑤dbfilename :**设置快照的文件名,默认是 dump.rdb
**⑥dir:**设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。
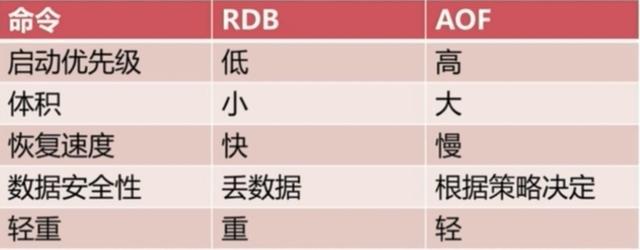
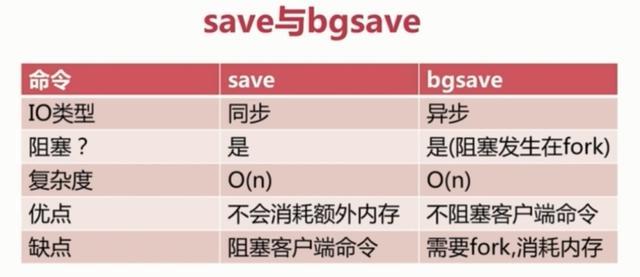
我们可以修改这些配置来实现我们想要的效果。因为第三种方式是配置的,所以我们对前两种进行一个对比:
4、RDB 的优势和劣势
①、优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
三、AOF机制(append only file)
全量备份总是耗时的,有时候我们提供一种更加高效的方式AOF,工作机制很简单,redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。每次都采取的是追加模式。
1、持久化原理
他的原理看下面这张图:
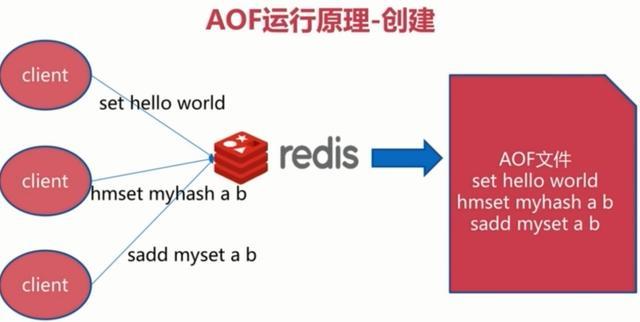
每当有一个写命令过来时,就直接保存在我们的AOF文件中。
2、文件重写原理
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。可以根据配置文件进行配置文件到达多大时重写aof文件。
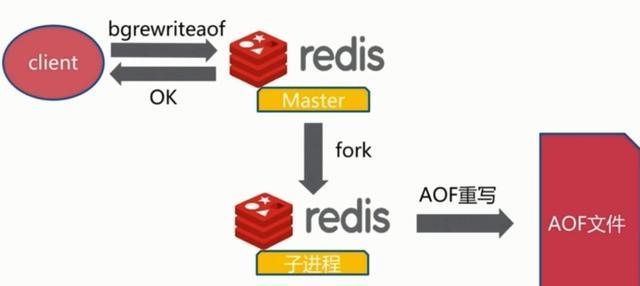
重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
3、AOF也有三种触发机制
(1)每修改同步always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
(2)每秒同步everysec:异步操作,每秒记录 如果一秒内宕机,有数据丢失
(3)不同no:从不同步

4、优点
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
5、缺点
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
四、RDB和AOF到底该如何选择
选择的话,两者加一起才更好。因为两个持久化机制你明白了,剩下的就是看自己的需求了,需求不同选择的也不一定,但是通常都是结合使用。有一张图可供总结: